Analysis 1b: Exploring options
First analysis
This is a repeat of the previous except that you should turn off Tree Pruning on the UserInput sheet. Do not change anything else.
First a reminder of the Results from the previous analysis. The previous image is shown followed by a short description of the tree and misclassification information.
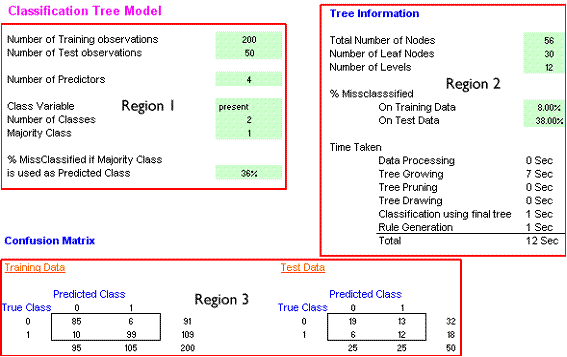
There are 56 nodes in the tree and 30 leaf (terminal) nodes. The tree has 11 layers. 8% of training cases are given the wrong label. 38% of the test cases are given the wrong label.
The training confusion matrix shows that 200 cases were classified, of which 91 had a true class of 0 and 109 had a true class of 0. 95 of the 200 cases were predicted to have a class of 0 and 105 to have a class of 1. Of those predicted to be class 0, 85 were correctly placed and 10 were incorrectly placed. Similarly, of the 105 predicted to be class 1, 99 were correctly identified and 6 were misclassified.
1 |
Comparing the pruned and unpruned treesDecide which statements are corect, there can be more than one. |
Second Analysis
Turn tree pruning back on. What are the consequences of using the first training / test option: use randomly selected rows?
On the UserInput sheet use the drop down menu to change the option to 1.

Also change the Option 1 to 25% of cases - this means that approximately 62 cases (250 x 0.25) will be retained for testing. The remainder will be used for testing. The screen should look like this.

Now run the same analysis three or four times and keep a note of the tree information on the Results sheet.
2 |
What are the effects of controlling the tree depth?
Make sure that
- pruning is turned on
- the training / test set option is set to 2 (Use last X rows), and that the number of rows is set 50.
Run the analysis with tree depth constraints of 4, 5, 6 and 7. You do this on the UserInput sheet, see below.

Make sure that the Maximum Depth option is ticked (but no others) and that the depth is either 4, 5, 6 or 7. You need to type the depth into this cell and press the Enter key to finalise this. Also build the tree with this option turned off, i.e. the tree is allowed to grow to its maximum pruned depth. Build the trees and make a note of the following from the results page.
Total Number of Nodes
Number of Leaf Nodes
Number of Levels
% Missclasssified
On Training Data
On Test Data
3 |
Best tree for training dataWhich tree depth produced the most accurate tree with training data? |
4 |
Accuracy with test dataWhich tree depth produced the most accurate results for the test data? |
5 |
Comparing tree depthsOne or more of the follwoing statements is correct. |